Labelling tasks for Machine Learning, such as ECG arrhythmia classification or detection of pneumonia from X-ray Images, require expert annotations, however, these experts do not have the bandwidth to label thousands of samples. This results in the generation of small datasets when compared to other fields, which creates a major challenge for AI in Medicine leading to issues with cross-patient generalization. Laussen Labs members, MASc candidate Dmitrii Shubin; Danny Eytan, MD, Ph.D.; Sebastian D. Goodfellow, Ph.D., have developed a novel Deep Learning model architecture called Variance-Aware Training (VAT), which was designed to address the issue of small labelled datasets.
We hypothesized that if the annotated dataset has enough morphological diversity to capture the variety within the general population, which is common in medical imaging for example due to similarities of tissue types, the variance error of the trained model would be the dominant component of the Bias-Variance Trade-off. The VAT method exploits this property of the labelled dataset by introducing the variance error into the model loss function, i.e., explicitly minimizing the variance error.
Our method was able to match or improve the state-of-the-art performance of self-supervised methods while achieving an order of magnitude reduction in the GPU training time. We validated VAT on three medical imaging datasets from diverse domains and various learning objectives. These included a Magnetic Resonance Imaging (MRI) dataset for the heart semantic segmentation, fundus photography dataset for ordinary regression of diabetic retinopathy progression, and classification of histopathologic scans of lymph node sections.
We are currently using VAT for the development of a model for real-time detection of heart arrhythmias, such as Junctional Ectopic Tachycardia, in critically ill children at SickKids. Preliminary results show a substantial boost of the model performance when compared to state-of-the-art baselines.
Paper Link: https://arxiv.org/abs/2105.14117
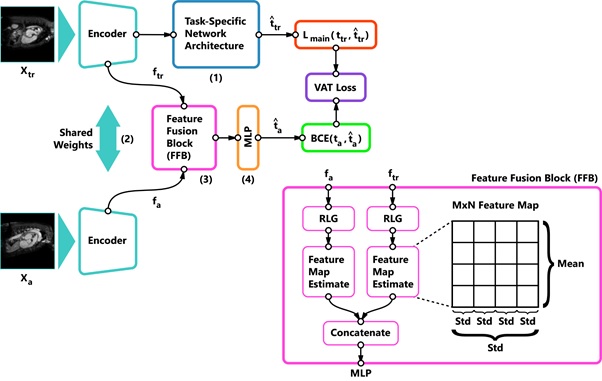
Generic structure of Variance-Aware Training framework. MLP (4) is tasked to classify if 2 images are part of the same subset (training or pre-training). Due to incorporated Reversed Gradient Layers (RGL), all gradients that lead to distinguishing subsets will be reversed, which leads to forgetting subset-specific information, i.e. explicit minimization of the model variance. After training, only the main network (1) will be used for inference.